
We receive everyday hundreds of users reviews and in natural langage processing this is what you call a gold mine!
Before being published a review needs to be...reviewed :D
A comment must follow our moderation guideline: it is considered inappropriate if it contains sensitive information, foul language etc.
If it was easy to do it manually at first, with the increasing volume it became urgent to have an automatic solution.
This solution is now live and use various algorithms, one of them is here ti detect what we call 'gibberish comments'. It is based on a really smart idea of Rob Neuhaus on stackoverflow
TLDR for the lazy: We use a 2 characters markov chain.
What is gibberish ?

Here is two comments we cannot publish :
« Mat e oa. Trugarez vras deoc'h. »
« llkhjlkklkkllkjkkjhjjjjljklhhk »
The first one is Breton, a language still spoken in the north west of France but we can only publish comments in French.
The second one speaks for itself.
Our gibberish detector can easily detect and reject those comments using a characters transition matrix.
What is a transition matrix ?
It is reaaaally simple.
Let's take the letter 'T'. In english, you can say that if you see a word with a 'T', you have more chance to see the letter 'E' following the 'T' than an 'X' for example.
The character transition matrix give us for every pairs of characters possible the probablity to meet them together.
Expl:
AA: 0.001
AB: 0.03
AC: 0.02
AD: 0.05
...
The sum of the probabilities for one letter will be equal to (P(AA)+P(AB)+P(AC)+P(AD)... = 1)
Let's say we have only three characters possible: A,B,C and we found the following pairs :
AA : 0 time
AB : 2 times
AC : 1 time
BA : 3 times
BB : 2 times
BC : 0 time
CA : 2 times
CB : 2 times
CC : 2 times
We write the following square matrix (row=first letter, columns=second letter)
A B C
A 0 2 1 ==> total of 3 occurrences
B 3 2 0 ==> total of 5 occurrences
C 2 2 2 ==> total of 6 occurrences
To get the probabilities, we just divide each cell by the sum of its row
A B C
A 0 2/3 1/3
B 3/5 2/5 0
C 1/3 1/3 1/3
Review score
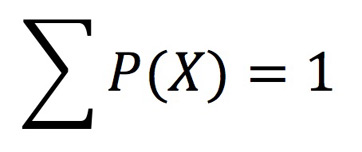
Using the aforementioned method and a set of reviews already manually moderated, we can generate our transition matrix. We will save it and use it to compute a score for each former and new review.
A review score is obtained by multiplying out the probabilities of its adjacent pairs of characters.
Using our previous example matrix, if our review is :
BACBABA
We can compute the score as
P(BA)*P(AC)*P(CB)*P(BA)*P(AB)*P(BA)
=> 3/5 * 1/3 * 1/3 * 3/5 * 2/3 * 3/5
=> 0.016
Since rare pairs have a low probabilty, the more rare pairs a review has, the lower its score.
Detecting gibberish strings
Using our manually moderated reviews set, we compute a minimum score for different review lengths (number of character).
Every time we need to moderate a new review, we compute its score with our probablity matrix and compare it with the minimum score for its length, if it lower then we can classify it as gibberish !